Adattárházak, adatbányászati
technológiák
(Utolsó módosítás:
2013. május 13. )
A kurzussal kapcsolatos levelezést, anyagok küldését a 2013adatbanya@gmail.com címre kérem.
Tematika:
Az adatfeltárás folyamata,
adatbányászat feladata. Adattárház építése, architektúrák, jellemző sémák,
adatkockák szerepe, műveletei. Adatelemzések, statisztikai jellemzők,
adat-transzformációk, távolságok. Asszociációs szabályok, paraméterek,
algoritmusok, példák. Osztályozási feladatok, algoritmusok, döntési fák,
példák. Klaszterezési feladatok, algoritmusok, példák. Adattárház építése
Oracle-ben. Adatbányászat Oracle-ben, illetve RapidMiner http://rapid-i.com/content/view/181/190/ programmal.
A kurzus teljesítéséhez szükséges
követelmények:
1 beadandó a félév során és egy írásbeli
vizsga a 8 vizsgakérdésekből.
A vizsgakérdést esszészerűen 2-3 oldalon
kell majd összefoglalni. Minden vizsgakérdés kidolgozásához elég az ezen az
oldalon szereplő slide-okból a lényeget megfogalmazni.
A beadandó teljesítése az írásbeli vizsgán
fél jegy felfele kerekítést fog érni.
Beadandó (március 18. 10 óráig):
A http://www.kaggle.com/c/job-salary-prediction
versenyre a Neptun kódotokkal megegyező néven regisztráljatok be és a hétfői
óráig egy osztályozással (pl. döntési fával) készített megoldást küldjetek be a
versenyre. Variáljátok a lehetséges paramétereket, hogy jobb eredményt érjetek
el. A döntési fára, vagy más osztályozásra épülő modellt a RapidMiner
segítségével állítsátok elő a train.csv-ből és alkalmazzátok az előrejelzést a
valid.csv halmazra, ahogy az előadáson megmutattuk. A versenyhez tartozó
halmazból kiszedtük a nagy szöveges oszlopokat, így az alábbi előkészített
halmazzal dolgozhattok: jobsalaryselected.zip
A beküldés után ellenőrizzétek, hogy
felkerültetek-e a http://www.kaggle.com/c/job-salary-prediction/leaderboard
ranglistára.
Küldjetek egy levelet a 2013adatbanya@gmail.com címemre, hogy
hanyadik helyre kerültetek, és csatoljátok a leaderboard aktuális snapshotját
bizonyítékként.
A megoldást majd az órán mutatjátok be.
(Segítség a kiinduláshoz: egy lehetséges
döntési fa - train decision tree. )
Vizsgakérdések:
1. Az adatbányászat,
tudásfeltárás feladata, a tudásfeltárása folyamata, példákkal magyarázva..
2. Az adattárházak építése,
architektúrák, példákkal magyarázva.
3. Az adatkockák szerepe,
műveletei, példákkal magyarázva.
4. Az asszociációs
szabályok előállítása, példákkal magyarázva
5. Az osztályozás feladata,
a döntési fák előállítása, példákkal magyarázva.
6. A klaszterezés feladata,
két klaszterező algoritmus, példákkal magyarázva.
7. Szövegbányászati
módszerek.
8. Entity resolution.
A tankönyv:
ADATBÁNYÁSZAT
KONCEPCIÓK ÉS TECHNIKÁK
Jiawei
Han - Micheline Kamber

Oracle Warehouse Builder:
Oracle Dataminer:
cikkek
az alkalmazásokról például telefonos
ügyfelek lemorzsolódási valószínűségének becslése
Kapható: http://www.libri.hu/konyv/adatbanyaszat-1.html
Az előadások anyagai:
1. előadás Bevezetés
2 - 4. előadás Adatok előfeldolgozása (statisztikai ismétlés)
1. Feladat (Excel-ben): Adatok.xls
(kor, nem, balkezes,
cipőméret, magasság, utazás az egyetemig percben, valszám jegy, statisztika
jegy, adatbázis1 jegy)
- adjuk hozzá a
statisztikai elemző csomagokat, ha még nincsenek aktiválva
- Készítsünk leíró
statisztikákat:
- mi a valszám jegyek átlaga, módusza, mediánja, szórása
- Standardizáljuk a
magasságot
- Készítsünk hisztogramot
az utazás attribútumra
- Készítsünk pontdigaramot
a (balkezes, magasság) illetve a (cipőméret, magasság)-ra
- Mennyi a (nem, balkezes)
Jaccard-együtthatója
- Van-e kapcsolat a valszám
jegy és az adatbázis1 jegy között a diagramok alapján
- Készítsük el a párhuzamos
koordinátákat
- további feladatokat az
órán adok
2. feladat (Excel-ben)
- illesszünk egyenest a
magasság, cipőméret pontokra, mi az egyenes két paramétere, ábrázoljuk is az
egyenest a pontokkal együtt
- ábrázoljuk a magasság
eloszlásfüggvényét
- transzformáljuk a -1,1
intervallumba a magasság, utazás, cipőméret attribútumokat
- adjuk meg az utazás,
adatbázis-jegy, magasság (3x3-as) kovarianciamátrixát
- mennyi a valszámjegy és
az adatbázis jegy korrelációs együtthatója, mire következtethetünk ebből?
- készítsünk egyenletes
hosszú, majd egyenletes gyakoriságú hisztogramot az utazás attribútumra
- a cipő, magasság, utazás
attribútumokra hajtsunk végre főkomponens
analízist (az első főkomponens milyen lineáris kombinációként áll elő?)
3. feladat (Excel-ben)
- számoljuk ki a cipőméret
entrópiáját
- ha két részre akarjuk
vágni a cipőméret értékeit, mi legyen a vágási pont
4-5. előadás Adattárházak
4. feladat (OLAP)
Próbáljuk ki a http://www.assistmyteam.net/OLAPStatisticsAccess/
30 napos verzióját.
Készítsünk egy adatkockát
az indexbe bevitt jegyekre építve, értelmes dimenziókkal, mértékekkel,
tetszőleges adatokkal
Demonstráljuk a program
funkcionalitását, az OLAP műveleteket elmentett képernyőkkel.
6. előadás: Adatbányászat (gyakori halmazok, apriori algoritmus,
asszociációs szabályok)
A weka segítségével
előfeldolgozás és asszociációs szabályok, gyakori halmazok keresése
5. feladat Az apriori
algoritmus megvalósítása JAVA-ban (apriori.jar)
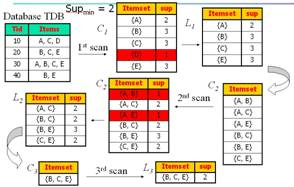
Input: (TDB, min_supp, k)
Output: Lk azaz a k elemű gyakori halmazok a TDB
tranzakciós adatbázisban
Tesztelés: A dián szereplő
mintafeladatra adja meg az L1, L2, L3 gyakori
egyelemű, kételemű, háromelemű halmazokat 50% min_supp-ra.
Feladat:
transaction id, items
1 A;B;E
2 A;B;D;E
3 B;C;D;E
4 B;D;E
5 A;B;D
6 B;E
7 A;E 1.
Mennyi a BD->E szabály support és confidence értéke? 2. Hajtsuk
végre az apriori algoritmust, írjuk fel az összes jelölt és gyakori halmazt! 3.
Írjuk fel az össze szabályt, amelyre (s,c) érték legalább (3/7,3/4)! 4.
RapidMiner-rel is oldjuk meg a feladatokat!
7. előadás
Adatbányászat
(osztályozás, döntési fák)
A weka segítségével
osztályozási feladat megoldása
8. előadás
A weka
segítségével klaszterezés
Ispány Márton fordítása:
Feladat:
Generáljunk a (0,0) (1,1)
és az (1,1) (2,2) két egységnégyzetben véletlenszerűen 100-100 pontot (például
Excel segítségével).
Legyen a séma (id, x,y,
label) label =1 vagy 2, attól függően, hogy melyik négyzetből származik a pont.
1. RapidMiner-ben k-mean
segítségével klaszterezzük k=2. Mennyi a hiba (hány pont kerül rossz
klaszterbe)?
2. k=3 –ra is
klaszterezzünk. Hasonlítsuk össze a két klaszterezést.
3. A http://cs.joensuu.fi/sipu/datasets/
oldalon található mintahalmazok közül válasszuk ki a http://cs.joensuu.fi/sipu/datasets/jain.txt
-t.
Egészítsük ki a sémát
id-vel: id, x,y, label
Klaszterezzük k-mean és
dbscan-nel. Melyiknél lesz kisebb a hiba?
A fóliák angolul:
081.ppt
082.ppt 083.ppt 084.ppt
Sidló Csaba: Entity Resolution

Weka ingyenes adatbányász eszköz
weboldala
Letöltött
telepíthető verzió (windowsra)
Bodon
jegyzet Weka kiegészítésekkel magyarul (2010. januári váltoizat)
Mintaadatok weka
feldolgozáshoz
Alkalmazott
adatbányászat tárgy (Wekára és Oracle Dataminer használatára épül)
Wekán alapuló
adatbányászati kurzus
Oracle tábla elérése
wekából oracle jdbc-n keresztül (hasonlóan lehetne postgresql-t is elérhetővé
tenni):
-
Töltsük le az oracle jdbc-t például a c:\Program Files\Weka-3-6
könyvtárba.
-
A weka.jar\experiment-ben
a DatabaseUtils.props.oracle -t nevezzük át DatabaseUtils.props -ra.
o
Az adattípusok
konverzióját (vagyis melyik oracle típusnak, melyik weka típus feleljen meg) is
a DatabaseUtils.props -ban kell megadni.
Például
ha szerepel a táblában ilyen adattípus, akkor be kell szúrni az int8=5 és numeric=2 sorokat.
o
A weka.jar-t
winrar-ral vagy NC-rel is meg lehet nyitni. Ha az átnevezés, editálás nem megy
közvetlenül, akkor másoljuk előbb ki egy könyvtárba, editáljuk, nevezzük át, és
másoljuk vissza.
-
Aki nem akarja
maga átnevezni, az átnevezés utáni weka.jar -t innen
letöltheti és ezzel cserélje le az eredetit.
-
A RunWeka.ini
fájlban a cp útvonalak közé vegyük fel az oracle jdbc jar fájl útvonalát (/ az
elválasztó jel!) és állítsuk nagyobbra mondjuk 1 gigásra a java memóriát. Ezzel
a módosított RunWeka.ini -vel cseréljük le az
eredetit.
-
A RunWeka.bat
-tal indítsuk a wekát.
-
Az Open DB
lapon lehet elérni az adatbázist. Előbb User, majd Connect műveletek után
tetszőleges SQL lekérdezés kiadható. (Figyelem, ha adatkezelést csinálunk,
COMMIT is kell majd a végén.)
-
A lekérdezés
után az OK-ra kattintva beolvassa a memóriába az adattáblát és a weka számára
átkonvertálja, és innen kezdve ugyanúgy használható, mint egy sima arff weka
adatfájl.
ROC görbe: roc.pdf
Egy osztályozási
esettanulmány: Paper25.pdf