Megjegyzések a magyar ékezetes betűkkel kapcsolatban
|
A pandora-t és valerie-t átállították UTF-8 kódolásra.
A panda ISO-8859-2 (más szóval közép-európai Windows, más szóval Latin2) kódolást használ.
Röviden és hosszabban segíteni szeretnék abban, hogy ne legyen gond az ékezetekkel kapcsolatban. Röviden (annak, akit csak a recept érdekel):
Az előbbiek technikai megvalósítása:
|

|
Az olvassa tovább, akit részletek és összefüggések is érdekelnek.
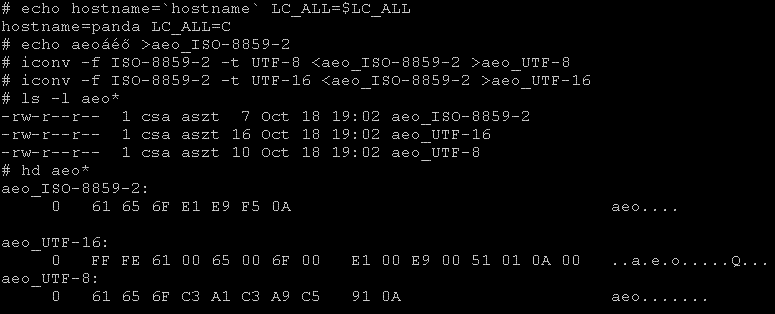
Az angol ABC kiváltságos helyzetben van, a többinek az "egyéb" jelei hányatott sorsúak a számítógépeken. Az angol ABC betűinek 7-bites kódja van, úgy, hogy az ABC-be rendezés egyszerű kódérték szerinti (numerikus) rendezés. Az európaiak betűi az ISO-8859-es kód szabványban a felső byte tartományba kerültek, oda is egymást váltva (az egyes nemzeteké), és nem nemzeti ABC sorrendben. Másoké (kínai, japán, héber, stb.) oda sem férnek be. Ezek tárolására találták ki az Unicode szabványt, aminek a különböző kódolásai egynél több byte-ot használnak a szóbanforgó jelek kódolására. Az alábbi példában a panda-n, ISO-8859-2-es alapbeállítás mellett fájlba tettem az "aeoáéő" jeleket, majd előállítottam a fájl UTF-8 és UTF-16 kódolású megfelelőit.
A példában szereplő "hd" (hexa dump) program egyéb Unixból lett Linuxba befordítva. A pand(or)a-n a "/h/public/c/csa/hd" fájlban megtalálható. (De 2008 októberben nincs is rá szükség, pillanatnyilag tartalmaz hd parancsot a Linux installáció.) Látható, hogy az ISO-8859-2 egy jellel kódolja az áéő betűket is, az UTF-8 az angol ABC betűit ugyanígy, az áéő betűket viszont 2-2 jellel. Az UTF-16 mindent (még a sorvége jelet is) két jellel, a szöveg két kezdőjele jelzi, hogy UTF-16 kódolású a szöveg. Az ő betű az egyes kódolásokban:
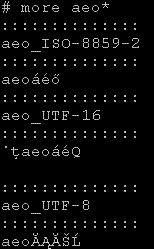
Ha more paranccsal megnézzük a fájlokat, akkor akár a panda, akár a pandora azt mutatja jól, ami a kiindulási gépen beállított kódolásnak (alapbeállítás) megfelel.
A putty ill. konsole programokhoz az első részben leírt módon lehet UTF-8-as alapbeállítást is létrehozni. A példából úgy tűnik, hogy csak az alapbeállítás számít, de ha a pandora/panda környezetváltozó beállítások nem felelnek meg az alapbeállításnak, akkor ékezetes betűk beírásakor "furcsa dolgok" történnek. Ezt mindenki kipróbálhatja maga, nem sok öröme lesz benne. Konkrétan ez azt jelenti, hogy a panda-ra ISO-8859-2-es alapbeállítással menjünk, a pandora-ra pedig vagy UTF-8-al (de ne a beadandók miatt), vagy ISO-8859-2-vel (a beadandók miatt), de utóbbi esetben a c paranccsal állítsuk át a panda-hoz hasonló viselkedésre. A pandora-n az alias parancs mutatja a lehetséges környezetváltozó beállításokat.
Sok program viselkedése függ ezektől a beállításoktól. Pl. a pine levelezőprogramban "C" beállítással nem tud ékezetes betűket beírni. Vagy pl. a sort eszerint rendez. Jól vagy rosszul, lassabban vagy gyorsabban (pl. az UTF-8-as rendezés több nagyságrenddel lassabb lehet, mint a "C"-s). Sajnos a pand(or)a rendezőprogramja "hu_HU" beállításra - szerintem - hibás. Az alábbi példa mutatja, hogy jó sorrendbe rakja az ékezetes betűket,
de a helyközöket, pontot semmibe veszi, emiatt elég furcsa a rendezés eredménye.
Még váratlanabb az, hogy hu_HU.UTF-8 (vagyis utf8) beállítás esetén (pandora, valerie) a reguláris kifejezések "[A-Z]"-je a kisbetűket is jelenti!!! Van, aki szerint ez jó, mert ez az "akadémiai rendezési szabály". Szerintem súlyos hiba a dolog. Ha egy rendszerben van kis-/nagy-betű megkülönböztetés, akkor egy program módosíthatatlan beállítása nem lehet az, hogy ettől eltekint. A sort-nak van "-f" opciója, a grep-nek van "-i" opciója arra, hogy ne különböztesse meg a kis- és nagybetűket, az ellenkezőjére viszont nincs opciójuk. A "-f" ill. "-i" ilyen kéretlen bekapcsolása - jelkódolástól függően - több, mint udvariatlan lépés. Tehát a sort program használata esetén NE válasszon ISO-8859-2-es (azaz "hu_HU") környezetváltozó beállításokat. Van, amikor mégis kellhet "hu_HU". A pand(or)a-n a rev csak ekkor hajlandó magyar ékezetes jeleket tartalmazó sorokat is feldolgozni! Ehhez elég a megfelelő script elejére betenni az export LC_ALL=hu_HU sort. (Az itt szereplő másik három környezetváltozót a man bash szerint az LC_ALL felülbírálja, de "biztos, ami biztos" alapon mindig állíthatjuk mind a négyet.) A jövő várhatóan az UTF-8 egyre nagyobb elterjedését hozza majd. Addig is írjuk majd egymásnak a sok alig olvasható ékezetekkel telerakott, vagy ékezetek nélkül makogó levelet. Bábel tovább büntet. Végül megjegyzem, hogy minden itt leírt "bölcsesség"-re rá tudnak cáfolni egyes gépek ill. helyzetek. |