Telekommunikációs hálózatok > Előadás anyag > Adatkapcsolati réteg
2. Adatkapcsolati réteg
Az adatkapcsolati réteg feladatai, az adatok keretekre tördelése, hogy ne legyenek hosszú bitsorozataink, így ne legyen annyi hibalehetőség és ne kelljen mindent újra küldeni. A közeghozzáférés vezérlés (MAC), azaz ha többen használnak egy közeget egyszerre, akkor dinamikusan osztja szét a kapacitást. A hibákat algoritmussal oldja fel. A Per-hop megbízhatóság is feladata, azaz ha átküldünk egy bitsorozatot, az helyesen érkezik-e meg és a folyamvezérlés is feladata, azaz egy gyors adó nem terhelheti túl a lassú vevőt.
Keretképzés:
Keretekre bontjuk a bitfolyamot. A fizikai réteg nem garantál hibamentességet, ezért a javítás az adatkapcsolati réteg feladata. Erre egy ellenőrző összeg szolgál, amit csatolunk a keretekhez, hogy a hibákat fel lehessen ismerni vagy ki lehessen javítani. Észlelni kell a keret elejét és végét a fogadó oldalon.
A keret képzés fajtái:
- Bájt alapú protokollok
- Bit alapú protokollok
- Óra alapú protokollok
Bájt alapú protokollok:
Karakterszámlálás:
Bájtonként küldjük az adatokat és a keret fejlécében szereplő mezőben megadjuk a keretben lévő karakterek számát. Viszont lehet, hogy egy ilyen karakterszámláló hibásodik meg.

Bájt beszúrás:
Egy speciális FLAG bájttal vesszük körbe az adatot. Ha az adatban előfordul ez a FLAG bájt, akkor egy ESC bájtot szúrunk be a FLAG bájt elé. Ha viszont az ESC bájt fordul elő az adatban, akkor az elé is beszúrunk egy ESC bájtot. Legrosszabb esetben minden adatbeli bájt ESC vagy FLAG és ekkor 50%-os a teljesítmény csökkenés.

Bit alapú protokollok:
Minden keret egy speciális bitmintával kezdődik és végződik. Ha előfordul az adatban is ez a bitminta, akkor a küldő az adatban előforduló minden 11111 részsorozat elé 0-ás bitet szúr be (ez speciálisan a High-level Data Link Protocol (HDLC) esetén van). Ezt nevezzük bit beszúrásnak.


Óra alapú keretezés:
SONET (Synchronous Optical Network):
Minden keret mérete ugyanakkora a szabvány szerint. Minden keret speciális mintával kezdődik. Ha sikerül megtalálni ezt a mintát, akkor megvan a keret eleje. Mivel minden keret ugyanannyi bájt, ezért a kiküldési idő is ugyanannyi lesz, ezért tudjuk, hogy a detektálástól mennyi időnek kell eltelnie, míg az utolsó bájt is beér.
Hibafelügyelet:
Bit hibák definiciója:
Egyszerű bithiba: Csak egy bit hibásodik csak meg.
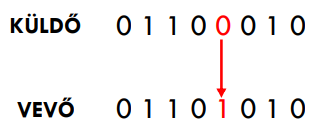
Csoportos bithiba (burst error): Több bit hibásodik meg. Itt m a legszűkebb hibás részből oly módon kapott minimális szám, amelyből ha m egymást követő bitet kiválasztunk, biztosan lesz benne legalább egy bithiba (pl m=1-nél mindegyik bit hibás egy adott részen folytonosan). Ebben a részsorozatban nem létezik olyan m hosszú részsorozat, amelyet helyesen fogadtunk volna.
Hibadetektálás:
Naiv hibadetektálás:
Kétszer küldünk el minden keretet. Viszont így a hatékonyság jelentősen lecsökken. Lényegében a duplán elküldött adat azt jelenti, hogy kétszer akkora esélye lesz a meghibásodásnak. Gyenge hibavédelemmel rendelkezik. Túl nagy a költsége.
Paritás bit:
Extra biteket adunk a bitsorozathoz úgy, hogy az egyesek száma páros legyen. Ezzel a módszerrel 1 bithiba detektálható, 2 bithiba már nem. Csoportos hibák esetén nem megbízható.
Hiba vezérlés:
A hiba javító (Forward Error Correction (FEC)) kódokat a kevésbé megbízható csatornákon (pl mobilhálózatnál) célszerű használni. Míg a hiba detektálás és újraküldés (Automatic Repeat Request (ARQ)) módszerét a megbízhatóbb csatornákon érdemes használni.
Redundancia
Alapból 2^m üzenet írható le m biten. Ekkor egy helyes kódból egy darab bithibával egy teljesen másik kód fog előállni. Ilyen esetben nem fogjuk tudni eldönteni, hogy hiba van-e a kódban. Ezért kiegészítjük r redundáns bittel (ellenőrző bittel). A keret hossza m+r=n lesz. Viszont így már nem az összes 2^n darab lehetséges kód lesz helyes. Csak azok lesznek helyesek, ahol az ellenőrzés nem talál hibát. Fontos megjegyezni, hogy minél több ellenőrző bitet rakunk bele, annál több bithibát vagyunk képesek detektálni, de ekkor a hatékonyság is romlik.
Hamming távolság:
Az olyan bitpozíciók számát, ahol a két kódszóban különböző bitek állnak, két
kódszó Hamming-távolságának
nevezzük. Ez gyakorlatilag azt mondja meg, hogy hány bit különbözik. S az egyenlő hosszú bitszavak
halmaza d(x, y) két kód Hamming-távolsága d(S) = min d(x, y). Ez azt mondja
meg, hogy hány bithiba eredményez egy új helyes kódot.
Pl. d(11111, 11000) = 3
d(S) = 1: Nincs hibafelismerés. 1 bit megváltoztatása új kódot eredményez.
d(S) = 2: 1 bithiba felismerhető vele, de nem javítható, mert nem tudjuk, hogy melyik kódra
javítsuk.
Mindig a legközelebb álló helyes kódra javítjuk.
d Hamming-távolság esetén d-1 hiba detektálható. k Hamming-távolság esetén (k-1)/2 hiba
javítható. Hamming-távolsággal az a baj, hogy különböző hosszú kódszavakra nem
használható, nem lehet őket összehasonlítani.
- R_{S} = log2 |S| / n a kód rátája, ahol S a kód
- \delta_{S} = d(S) / n a kód távolsága, ahol S a kód
A jó kódnak a rátája és a távolsága is nagy.
Paritás bit:
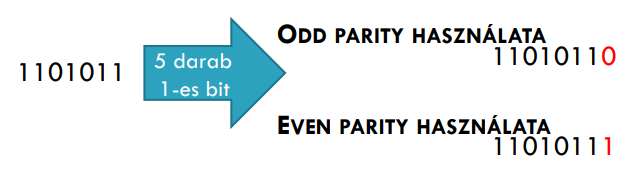
A paritásbitet úgy választjuk meg, hogy a kódszóban levő 1-esek száma páros (vagy páratlan) legyen.
- Odd parity: Ha az 1-esek száma páratlan, akkor 0 befűzése; egyébként 1-es befűzése
- Even parity: Ha az 1-esek száma páros, akkor 0 befűzése; egyébként 1-es befűzése
A Hamming-kód a paritásbitet használja. A biteket megszámozzuk 1-től és minden kettőhatvány egy ellenőrző bit lesz, a maradék bitek lesznek az üzenet bitjei. A k-adik bitet fel lehet írni kettőhatványok összegeként.
Hamming kód példa:
3 = 1 + 2
5 = 1 + 4
6 = 2 + 4
7 = 1 + 2 + 4
9 = 1 + 8
10 = 2 + 8
11 = 1 + 2 + 8
Az ellenőrzőbiteket úgy számoljuk ki, hogy ha pl. az első ellenőrzőbitet szeretnénk kiszámolni, megnézzük melyekhez használtunk 1-est, az összeadásnál. Megnézzük, hogy a 3., 5., 7., ... pozíciókban hány darab 1-es van. Ha ez páratlan, akkor 0 kerül az első ellenőrző bit helyére.
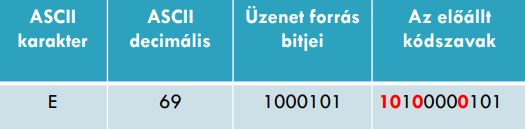
Első ellenőrzőbit kiszámolása a Hamming kódban:
Ezekben az összegekben szerepel 1-es: 3., 5., 7., 9., 11.
Ezeken a pozíciókon ezen számok szerepelnek: 1, 0, 0, 1, 1
Tehát 3 darab 1-es van. Ami páratlan, tehát 1-est írunk az első ellenőrző bit helyére.
Vevő oldalon lesz egy számláló, ami a helytelen kettőhatványú biteket fogja összeadni. Ha a számláló nem nulla, akkor hibás a kód és a hibás bit sorszámát tartalmazza a számláló, azaz ha pl. az első, a második és nyolcadik bit helytelen, akkor a megváltozott bit a tizenegyedik.
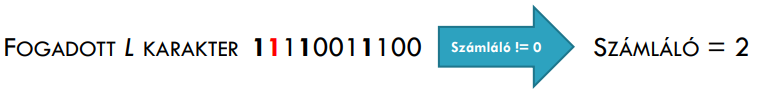
Hibajelző kódok:
Csak detektálunk, nem javítunk. Csak újra küldéssel javítható a hiba. Ez a megbízhatóbb csatornáknál hasznos. Ezeket a láblécbe rakjuk.
Ciklikus Redundancia Kódok (CRC):
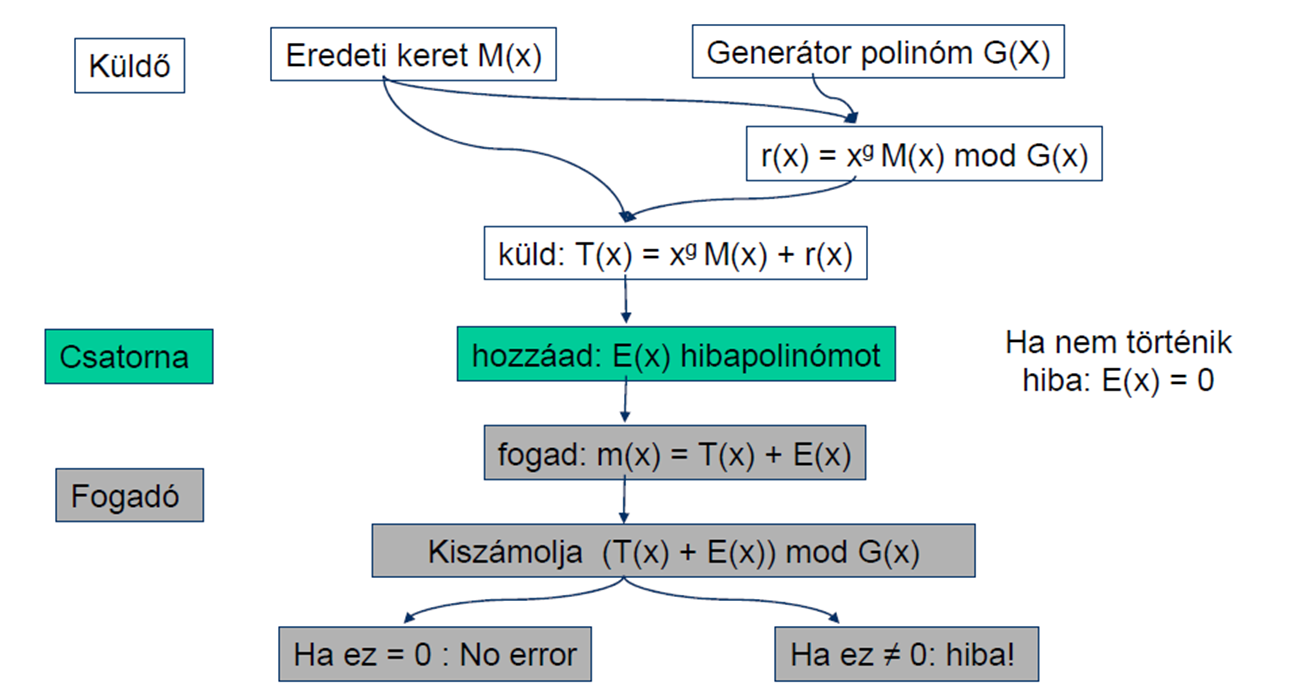
A bit sorozatokat egész együtthatós polinomok reprezentálják. Pl. 1010 \rightarrow p(x) = 1x^3 + 0x^2 + 1x^1 + 0x^0. Két polinomnak az összege megegyezik a kizáró vagyolásukkal (XOR). Kell egy generátor polinom, ezt mindenkinek ismernie kell, ez általában része a szabványnak. Egy olyan polinomot küldünk át, hogy az többszöröse legyen a generátorpolinomnak. Ennek a polinomnak lesz egy adat része és egy ellenőrző része.
Eredeti keret: M(x)
Generátor polinom: G(x)
g-vel arrébb shift-elt eredeti keret, azaz g darab 0-át írtunk a végére: x^g * M(x)
Ha ezt az arrébb shift-elt polinomot leosztjuk a generátor polinommal, akkor a megkapjuk a
maradékpolinomot: r(x) = x^g * M(x) mod G(x)
A maradékpolinomot beírjuk a g darab 0 helyére és kész az üzenetünk.
Ha a generátorpolinom pl. negyedfokú, akkor a kontrollösszeg, azaz a maradékpolinom négy biten ábrázolható.
A vételi oldalon megnézzük, hogy a kapott bitsorozat osztható-e a generátorpolinommal és ha igen, akkor nincs hiba vagy a hibapolinom osztható a generátorpolinommal. Ha a generátorpolinomnak többszöröse a polinom, amit vételi oldalon kaptunk, akkor nem képes detektálni a hibát.
Példa:
Keret: 1101011011
Generátor: 10011 (negyed fokú)
Maradék polinom: 1110 (négy biten ábrázolható)
A továbbítandó üzenet: 1101011011 1110
Forgalomszabályozás:
A gyors küldő eláraszthatja a lassú vevőt. Erre két féle megoldás:
- visszacsatolás alapú: A vevő engedélyezi a küldőnek, hogy küldhet-e adatot.
- sebesség alapú: Protokollokba épített sebesség korlát, de ezt ez a réteg nem használja.
Kommunikáció fajtái:
- szimplex: egyirányú
- fél-duplex (half-duplex): két irányú, de egyszerre csak egy irány aktív
- duplex: két irányú
Folyamvezérlő protokollok:
Korlátozás nélküli szimplex protokoll:
A küldő folyamatosan küld a vevőnek várakozás nélkül. A hibátlan kereteket a végtelen puffer miatt el tudja tárolni a vevő.
Szimplex megáll-és-vár protokoll (stop-and-wait protocol):
A küldő nem küld addig, amíg nem kapott nyugtát. Ha a vevő megkapott egy keretet, \Delta t időre van szüksége a bejövő keret feldolgozására (nincs pufferelés és sorban állás sem), ez után nyugtát küld. Ide már nem elég a szimplex csatorna, fél-duplex kell.
Szimplex protokoll zajos csatornához:
\Delta t idő kell itt is egy keret feldolgozásához, nincs puffer, se sor, de megsérülhetnek a keretek. A küldő most is akkor küld valamit, ha az előző nyugtáját megkapta. Ha nem kapja meg időben a nyugtát, elküldi megint a keretet. Emiatt viszont duplikátumok jelenhetnek meg, ha a nyugta veszett el.
Ekkor el kell dönteni, hogy láttuk-e már a keretet vagy sem. Ezt sorszámozással lehet megtenni, erre lesz jó az alteráló-bit protokoll (ABP). Tehát szimplex protokoll zajos csatornák esetében a nyugta elvesztese esetén duplikátumok adódhatnak át a felsőbb rétegeknek a fogadó oldalon.
Alteráló-bit protokoll (ABP):
Elég egy egy-bites sorozatszám. Ez lehet 0 vagy 1. A küldő kezdetben 0-val ellátott keretet küld. Nyugtáig nem küld újat, vagy az idő lejártáig. A vevő a 0-ás sorszámú keretre vár. Ha hibátlan a keret, akkor lépteti a sorszámot és a nyugtában egy 1-est küld vissza, azaz a következő elvárt sorszámú keretet. Hiba esetén nem nyugtáz. Nagy propagációs idő esetén nem hatékony, viszont nagy csomagok esetén hatékony. 50%-os kihasználtság érhető el vele. Kihasználtsága azonos a Szimplex protokoll zajos csatornához protokollal.
Hatékonyság javítása:
Full duplex csatornát használva a küldő folyamatosan küldhet a nyugta megvárása nélkül, de nem szabad túlterhelni a vevőt. Célszerű folyamatosan küldeni a kereteket, majd várni mindegyik nyugtájára. A sorszámokat ki kell ilyenkor terjeszteni.
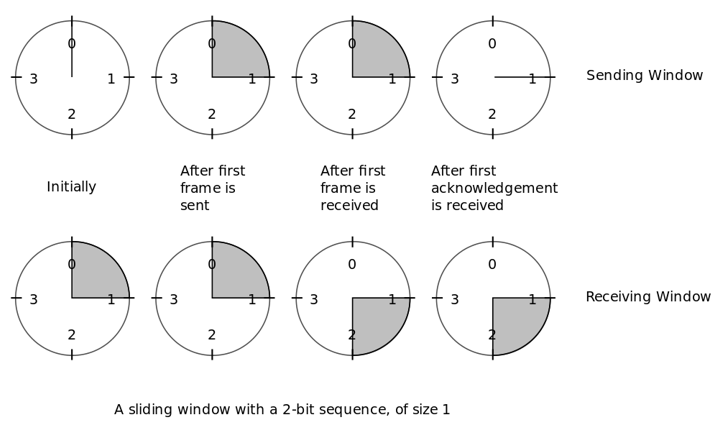
Csúszó-ablak protokoll:
Ez a ABP protokoll kiterjesztése több bitre. Egyszerre n keretet (összesen ablak méretnyi) küldhetünk ki, hogy elférjen a fogadó n keretnyi pufferében. A keretek sorszámot kapnak ciklikusan. A fogadó már kumulatív nyugtázást végez, azaz több keretet nyugtázhat egyszerre. Mindig a következő elvárt keret sorszámát küldi vissza a nyugtában. Tehát a nyugtában szereplő sorszámnál nála kisebbek megérkeztek.
Van egy küldő és fogadó ablakunk. A küldő ablak azt mutatja, hogy mik azok,
amiket kiküldtünk, de nem
jött még rá nyugta. A vételi ablak azt mutatja, hogy milyen sorszámokat várunk. Ennek mindig fix a
mérete.
Ha nincs benne a vételi ablakban egy sorszám, akkor eldobja és küld egy nyugtát, hogy mi a
következő,
amit vár.
Piggybacking módszer: Kétirányú kommunikációnál (duplex), a kimenő nyugtákat késleltetjük, hogy a következő kimenő keret ACK mezőjét használva nyugtázzuk a kereteket.
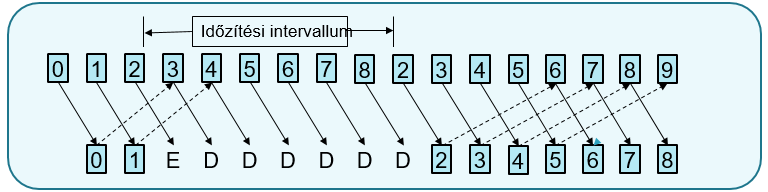
Visszalépés N-nel:
Egy hibás keret utáni összes keretet eldobjuk és nem küldünk nyugtát. A küldő az idő lejárta után újra küldi a nyugtázatlan kereteket. Ha a vételi ablak mérete 1, akkor sorrendben kell jöjjenek a keretek, de ez nagy sávszélességet pazarolhat.
Szelektív ismétlés:
Negatív nyugtát küld a vevő (NAK). Ez megmondja, hogy melyik keret érkezett meg és melyik nem.
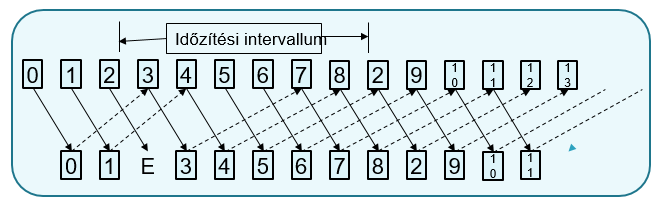
Ethernet keret:

- preamble: ahhoz kell, hogy megtaláljuk a keret elejét
- MAC destination: vevő MAC címe (3 byte gyártó azonosító, 3 byte eszköz azonosító)
- MAC source: küldő MAC címe (3 byte gyártó azonosító, 3 byte eszköz azonosító)
- Ethertype: milyen magasabb szintű adategységet tartalmaz a keret, milyen enkapszuláción megy keresztül a keret
- Payload: maga az üzenet
- CRC checksum: ellenőrző összeg
- interframe gap: rés, hogy a keretek ne csússzanak egymásra
Közeghozzáférés vezérlése (MAC):
Egyidejű átvitel ütközést (collision) okoz, ezeket vagy elkerüljük vagy valahogy feloldjuk. Itt csak a dinamikus csatornakiosztás működik. Ennek két féle időmodellje van. Folytonos, ahol mindegyik állomás tetszőleges időben kezdhet küldeni. A másik a diszkrét, amikor az időt diszkrét résekre osztjuk, ilyenkor a keretek küldése csak az időrés elején lehetséges. Lehet vivőjel érzékelési képesség is, ami azt jelenti, hogy bele tud hallgatni a csatornába, hogy éppen valaki használja-e vagy sem.
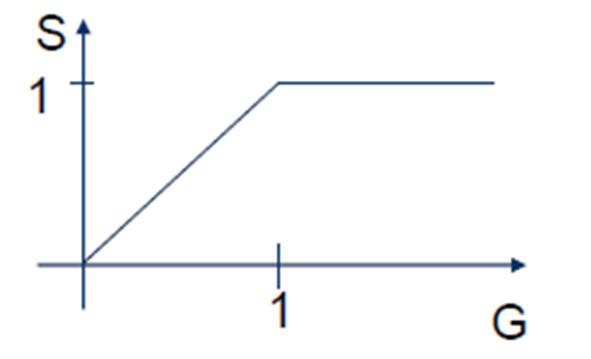
Átvitel és terhelés:
G (terhelés), átviteli kísérletek száma. Egy időegység alatt, egy keretet tud kezelni. Ha G > 1, akkor túl van terhelve a hálózat, ami csomagvesztést okoz.
S (átvitel), sikeres átvitelek száma. Ha G \le 1, akkor az átvitel megegyezik a terheléssel, azaz S = G. Ha G \ge 1, akkor az átvitel egy lesz, mert egy keretet tud átküldeni egy időegység alatt, S = 1.
Ütközés alapú protokollok:
ALOHA protokoll:
Kis intenzitású hálózatok esetén használják, azaz ha nagyon kevés keretet küldenek, pl. naponta egyet. Az állomások akkor küldenek, ha van küldendő adat. Ekkor azonnal küldenek. A vevő minden keretet nyugtáz. Ha a küldő nem kapta meg a nyugtát, egy idő után újra küldi.
- T_{f} idő
- S átvitel
- G terhelés
- D késleltetés
Sebezhetőségi idő: Az az intervallum, amelyben a csomagok átfedésben lehetnek, ezzel megakadályozva az átvitel sikerességét. ALOHA esetében ez 2T_{f}.
A jó átvitelek valószínűsége (S = G * x), megegyezik azzal a valószínűséggel, hogy a sebezhetőségi idő alatt nincs beérkező keret. Ha kicsit a terhelés nagy valószínűséggel mennek át a keretek, nagy terhelés esetén kicsi a valószínűsége.
- G = 0.5
- S(G) = 0.18, azaz 18% csatornakapacitás érhető el.
Minden állomás azonnal küldhet, ezért kisebb a várakozási idő, de kisebb a csatornakihasználtság is.
Réselt ALOHA protokoll:
A csatornát felbontjuk időrésekre. Ezeknek az időréseknek a hossza 1 keret átviteléhez szükséges idő. Csak a rések elején lehet küldeni. Ez egyfajta szinkronizációt képez. Így a sebezhetőségi idő a felére csökken. Ezzel a megoldással 37% csatornakapacitás érhető el.

TDMA:
Ahány állomásunk van, annyi részre van osztva az idő, így sokat kell várni. Minden állomásnak meg kell várnia a saját körét. A várakozási idő arányos az állomások számával.
CSMA:
Minden állomás bele tud hallgatni a csatornába (vivőjel érzékelés).
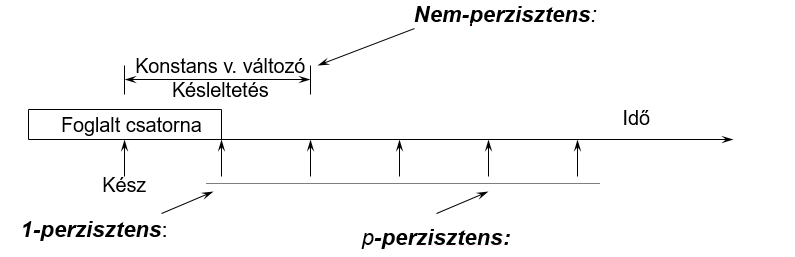
1-perzisztens CSMA:
Először belehallgat a csatornába, majd ha foglalt, akkor addig vár, amíg fel nem szabadul. Amint felszabadul, küldjük az adatunkat. Ezzel az a probléma, hogy ha többen küldenének egyszerre a keretek összeütköznek. Ezzel a megoldás jobb teljesítményű, mint az ALOHA protokollok.
nem-perzisztens CSMA:
Először belehallgat a csatornába, majd ha foglalt, akkor véletlen ideig vár, majd újra belehallgat a csatornába. Nem figyeli folyamatosan a hálózatot. Ha szabad a csatorna elküldi.
Kicsit terhelés esetén az 1-perzisztens jobb tud lenni, mert amint felszabadul a csatorna azonnal küldi. Viszont nagy terhelés esetén, ha több állomás is ugyanakkor küld, akkor keret ütközések lehetnek. Ezzel szemben a nem-perzisztensnél a véletlen várakozás ezt tudja orvosolni, de ilyenkor előfordulhat olyan, hogy már rég küldhetne, de még mindig vár. Feleslegesen várunk.
p-perzisztens CSMA:
Diszkrét időmodellt használ. Belehallgat a csatornába, ha foglalt, akkor vár a következő időrésig. Ha szabad a csatorna p valószínűséggel fog küldeni és 1-p valószínűséggel nem küld. Ha kicsi a p, sokáig várhatunk feleslegesen. Nagy terhelésnél jó lesz az átvitel. Ez még a nem-perzisztens CSMA-nál is jobban szétzilálja a küldéseket. Kicsi az esélye annak, hogy többen fognak küldeni egyszerre.
CSMA/Collission Detection (CSMA/CD):
Ezzel bármelyik CSMA-t ki lehet egészíteni. Ennek az a lényege, hogy nem csak küldés előtt tudunk belehallgatni a csatornába, hanem küldés közben is. Ha ütközést tapasztalunk megszakítjuk a küldést, mert nincs értelme tovább küldeni a kereteket. Később véletlen várakozás után újra próbáljuk. Ha nem volt ütközés a küldés közben, akkor sikeresen átment a keret.
Ha ütközést érzékel a küldő, kiküld egy "jam" jelet, hogy mindenki tudjon az ütközésről. Várunk k eleme [0, (2^{ütközések száma}-1] (random) időegységet az újra küldésig. Ha sok az ütközés az intervallum egyre csak nő, így az esélye kisebb az újbóli ütközéseknek.
64 bájt a minimális keretméret az ütközés-detektáláshoz: azért, mert ha nagyon kicsi keretet küldünk, akkor a propagációs késleltetés jelentősebb, így kisebb eséllyel vesszük észre az ütközést. Legalább a legnagyobb propagációs idő kétszereséig kell küldeni = adatráta (bit/s) * 2 * d(s) (ahol d = távolság (m) / fénysebesség (m/s)). A maximális keretméret (MTU) 1500 bájt szokott lenni. De van ahol érdemes kisebbet választani, mert kisebb keretekben egyszerűbb a hibadetektálás. De ilyenkor több header-t küldünk át.
Ütközésmentes protokollok:
Úgy ütemez, hogy ütközés nem történhet. Minden állomásnak van egy azonosítója [0, állomások száma] intervallumon. Ezeknél a protokolloknál réselt időmodellt feltételezünk.
Alapvető bittérkép-alapú protokoll:
Időrések vannak, ahova be kell jelenteniük, hogy mikor akarnak küldeni. Aki nem jelentette be az igényét, az nem küldhet. Tehát lesz egy bejelentő (versengő) fázis és egy küldési fázis. Sok állomás esetén sokáig tarthat a versengés. Legrosszabb esetben N a várakozási idő az adatkeret küldésére, N állomás esetén, a küldési fázisban.

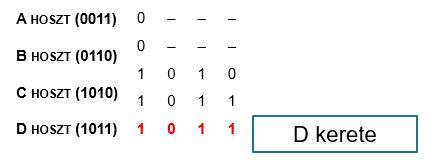
Bináris visszaszámlálás protokoll:
Minden állomás azonosítója N biten reprezentálható.
A versengési időtartamot úgy csökkentjük, hogy a versengési időszakban minden állomás azonosítójuk
első bitjét sugározza. Ha valaki sugárzott 1-est, akkor az eredő bit is 1-es lesz. Megnézik, hogy
ugyanaz lett az eredő, mint ami az ő első bitjük, majd ha igen, akkor folytatják a versenyt. Ha nem,
akkor nem küldenek. Ez viszont kiéheztetéshez vezethet, mert mindig a nagyobb azonosítójú küldő
nyer.
Mok and Ward módosítás ezt korrigálja. Ennek lényege, hogy virtuális állomás-azonosítókat vezetünk be fizikai helyett és ha valaki nyert, akkor az megkapja a legkisebb azonosítót, a többiek megnövelik eggyel a sajátjukat. Így tehát a legnagyobb azonosítójú állomás forgalmazott a legrégebben.
Korlátozott verseny protokollok:
Lehetnek ütközések. Ha van ütközés, akkor korlátozza a résztvevők hozzáférési lehetőségét a csatornához.
Adaptív fa protokoll:
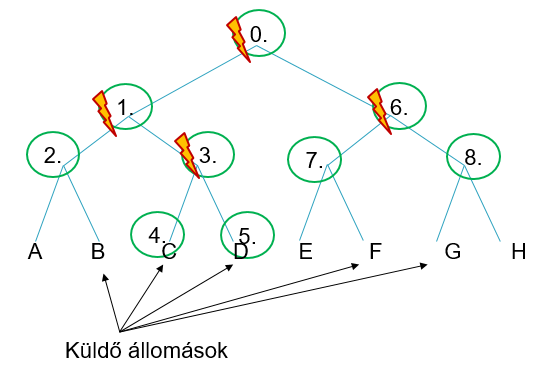
Diszkrét időmodellt használ. Az állomásokból egy bináris fát készítünk el (ők lesznek a levelek), majd időrésenként mélységi bejárást csinálunk a fán (preorder bejárás). Kezdetben mindenki küldhet. Ekkor a 0. időrésben, ütközés történik a fa gyökerében. Ezért megyünk lejjebb a fabejárással. Minden egyes bejárt csúcsnál azok a csúcsok küldenek üzenetet, akiknél vagy akik valamilyen felmenőinél tart a éppen bejárás. Ha valamilyen csúcsnál senki nem küld üzenetet, akkor annak a gyerekeit már kihagyjuk a bejárásból. Egészen addig megyünk lefele a bejárásban, amíg többen küldenek üzenetet ugyanabban az időrésben.
Eszközök:
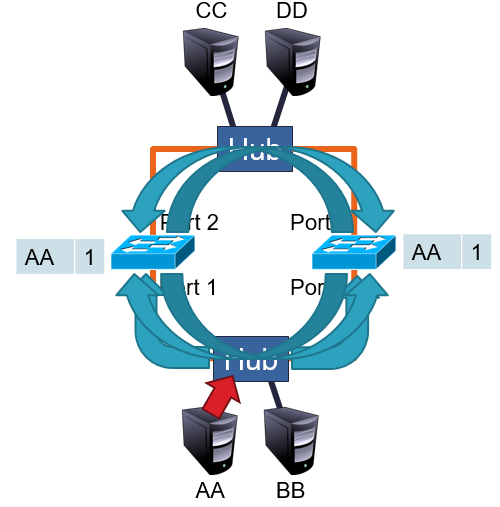
Hub:
Olcsó, de buta hardver. Több állomás esetén ütközések keletkeznek. Nem volt memóriája, hogy várakozási sorokkal megoldja az ütközéseket.


Bridge:
A mai switchek előzményei. Hardver cím alapján továbbítanak. Az ütközéseket
várakozási sorokkal oldják
meg, ha túl sok mindent küldenénk egy irányba, akkor sorba kerülnek a keretek. Konfigurálja önmagát,
az állomásokon nem kell átállítani semmit.
Funkciói: keretek továbbítása, MAC címek megtanulása, spanning tree protocol (STP).

Keret továbbítás:
Minden bridge rendelkezik egy továbbító táblával, amiben szerepel a MAC cím, hogy melyik portján van ez a MAC című eszköz és egy kor, ami azt mutatja, hogy mikor hallottunk róla utoljára. Ha túl régóta nem hallottunk róla, elfelejtjük. Több MAC cím is tartozhat egy porthoz.

MAC címek tanulása:
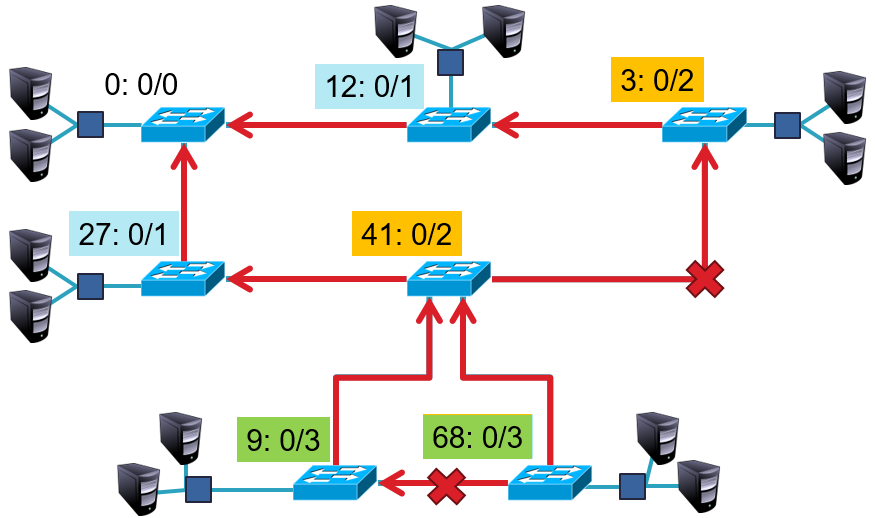
Kézzel is be lehet állítani a keret továbbító táblát, csak ez nem plug and play és nem dinamikus, ehelyett a bridgek automatikusan tanulják meg a MAC címeket. Ha érkezik egy keret ismeretlen forrás MAC címmel az egyik portjára, akkor ahhoz a porthoz bejegyzi a táblába a forráscímet. Ezen tábla alapján könnyedén tudjuk továbbítani a célcím felé a keretet. De ha nincs benne a táblában a célcím, akkor mindenkinek kiküldi, kivéve ahonnan jött a keret. Ezzel akkor van probléma, hogy ha van hurok a hálózatban, mert akkor végtelenségig küldhetik egymásnak a kereteket a bridgek. Ezeket a hurkokat meg kell szüntetni. Erre való a feszítőfa (spanning tree) protokoll.
Spanning tree protocol (STP):
A hálózatban lévő köröket szüntetjük meg az IEEE 802.1 feszítőfa (spanning tree) algoritmust használva. Több feszítőfa is lehet. Egyes feszítőfákban lehet hogy más terhelés jut a bridgekre, de az algoritmus lényege annyi, hogy kiválasztunk egy gyökér bridget, majd mindenki megkeresi a hozzá legrövidebb utat (ebből épül fel a feszítőfa). A feszítőfa építéskor a bridge-ek egymás között konfigurációs üzeneteket küldenek Configuration Bridge Protocol Data Unitokat (BPDU).
Configuration Bridge Protocol Data Unitokat (BPDU):
Tartalmaz egy bridge ID-t, minden bridgenek egyedi azonosítója van. Tartalmaz még egy gyökér ID-t, ez az, hogy a bridge kit hisz gyökérnek. Tartalmazza még az út költségét a gyökérhez, mennyi lépésből érjük el a gyökér bridget.
A legkisebb bridge ID-val rendelkező bridge lesz a gyökér, ez nem biztos, hogy jó, mert lehet hogy egy lassú bridge lesz a gyökér. Kezdetben mindenki azt hiszi, hogy ő maga a gyökér bridge. Mindenki BPDU üzeneteket küld el a szomszédjainak és felhasználja belőle az adatokat, hogy kialakuljon a feszítőfa.
Switch:
A switchek speciális bridgek, viszont minden porthoz egy állomás tartozik. Minden link full duplex, ezért nincs szükség CSMA/CD-re, mivel olyan eszközökkel állunk kapcsolatban, akik adatkapcsolati réteget használnak, tőlük nem kell külön ellenőrizni a keretet.
MAC-cím alapú útvonalválasztás, automatikus MAC cím tanulás és a hurokfeloldás itt is jelen van. A teljes internethez nem lehet switcheket használni, mert túl nagy lenne a továbbító tábla. Plusz az elárasztás nem lenne hatékony.
